MySQL的体系结构是一个由多个子系统构成的层次化系统,它封装着SQL接口,查询解析器,查询优化器和查询执行引擎,缓存/缓冲机制以及一个插件式存储引擎,具体如下图所示:
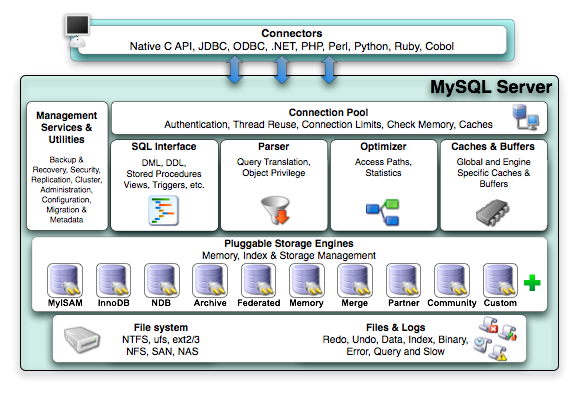
Connectors:一些用来与客户端应用程序建立连接的数据库接口,mysql能为各种编程环境都提供相应的数据库接口。
Management Services & Utilities: 系统管理和服务控制工具。
Connection Pool: 连接池,该层负责处理处理与用户访问有关的各种用户登录、线程处理、内存和进程缓存需求。
连接池的下一层是mysql数据库系统的核心,这里是对查询进行分析和优化的地方,也是对文件访问进行管理的地方。
数据库系统核心层的下一层是存储引擎层,这一层是mysql体系结构与众不同的部分之一,插件式存储引擎使得mysql系统可以灵活地适应各种数据或文件的存储检索机制。
插件式存储引擎的下面是mysql系统的最底层,即文件访问层,这一层是存储机制读/写数据,系统读/写日志和事件信息的地方,这一层也最贴近操作系统的层,与线程、进程和内存控制有关的操作都发生在这里。
SQL interface:提供了用户接收命令并把结果返回给用户的机制,mysql服务器从网络接收连接请求并为每个连接创建一个线程,每个线程在执行时都独立于其他线程,接收到SQL命令将存入一个类结构(class stucture),查询结果通过把有关数据写到网络通信协议上传回客户端.创建出一个线程之后,mysql服务器将开始解析SQL命令并把解析出来的各个部分保存到一个内部数据结构里去。
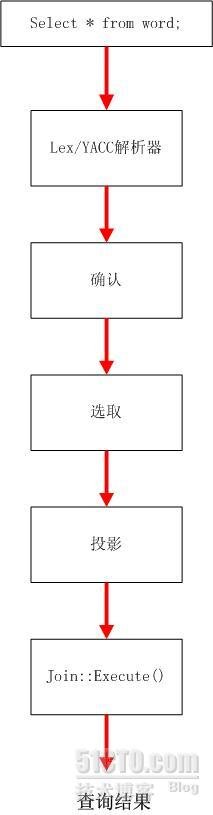
Parser:当收到客户端发出的查询并为之创建一个新线程之后,SQL语句将被传递解析器接受语法验证(或因错误而被拒绝)。mysql解析器是用一个很长的Lex-YACC脚本实现的(Lex-YACC脚本能够把一条SQL语句分解为命令字、选项和参数等一系列最基本的语法元素(记号)并把这些记号存入一个由变量和列表构成的结构),用Bison对该脚本进行编译就得到了这个解析器。解析器将构造一个用来在内存里代表查询语句(SQL)的查询结构,这个树状结构(也称为抽像语法树)可以用来执行查询,查询解析器只检查SQL语句的语法正确性。它不检查有关的表或字段是否存在,也不检查语法错误(比如使用了一个统计函数,但没有写出必要的group by子句的情况).这些事情将由优化器去检查。解析器生成的查询结构将被传递到查询处理器,从那开始的后续工作将由查询优化器负责控制。
Optimizer: 使用了”选取-投影-联结”策略来处理查询,即先根据有关的限制条件进行选取(select操作)以减少将要处理的元组的个数,再进行投影(对应于关系代数里的投影操作)以减少被选取元组里的字段的个数,最后根据联结条件生成最终的查询结果。mysql的查询优化器算不上是最复杂的,它采用的”选取-投影-联结”策略属于一种启发式查询优化机制,它使用的规则很简单:
1,通过计算where子句里的表达式来横向排除多余的数据。
2,只保留在字段清单列出的,以及在最后执行联结子句时还需要用到的属性(字段),其他数据全部排除。
3,根据联结条件生成最终的查询结果。
查询处理流程如下:
Caches & Buffers:缓存和缓冲区子系统负责保证使用频率最高的数据能够以最有效的方式被访问。绝大多缓存机制使用的相同或相似的概念:把数据封装为某种结构,再把这些结构保存为一个链表。如:表缓存,键缓存等。
本文出自 “一个SA的工作和学习记录” 博客,请务必保留此出处http://chlotte.blog.51cto.com/318402/401177


0 条评论。